


Maintenance staff, management, and the entire production department constantly prepare for unplanned failures. This means keeping contingency plans in the drawer and arming for every possible malfunction, then actually dealing with those situations in practice.
Daily operations in this environment puts teams in fire-fighting mode, and many manufacturing companies are stuck in this constant state. In this article, you’ll learn why this happens, why previous fixes haven't worked, and what you need to do instead to regain control.
Manual handling causes chaos on the shop floor
The reality on the shop floor involves constant manual handling. For example, when a pelletiser system breaks down (the system responsible for supplying or removing goods from the lines), 2 or 3 production employees must step in to manually load or remove the goods.
The "available capacity" trap
Supervisors often rope these employees into repairs because they have "available capacity" while the system is down. They are used for fetching and carrying spare parts and tools, tidying up, or diverting material flows.
Everyone involved is playing firefighter in a high-stress situation, trying to "get the cow off the ice". The technical department wears the hat because they are the only ones who understand which steps will remedy the malfunction.
Safety protocols slide when stress peaks
In this state, everyday life is inefficient. Time is lost to unplanned standstills and practising damage limitation. Work is a reaction to shouts, calls, and problems arising on the equipment.
This high stress level leads to a lack of structure where strictly prescribed rules are disregarded. Safety often suffers because the work must happen ad hoc to keep production losses low. Even supervisors look away from safety protocols, telling themselves they will process the incident afterward, only for the next malfunction to be handled the same way.
The situation triggers the "ant race". When a malfunction occurs, the maximum load hits the team because they are unprepared. Manpower might be available, but the material is missing or spare parts are packed in unknown boxes. Everyone is scrambling to find what they need.
Between these failures, the team tries to breathe and forge plans, but the complexity of modern sensor-based systems makes it impossible to prepare for everything without a proactive structure.
Non-maintenance tasks create a piling spiral
Furthermore, maintenance teams spend significant time on non-maintenance activities. Technicians are frequently tasked with hanging whiteboards, equipping offices with new technology, or assembling furniture.
This creates a piling spiral: the department is understaffed, tasks are pushed onto technology, and trouble follows when actual maintenance is missed because the team was busy with office furniture.
Why Excel and legacy tools fail
Most companies attempt to implement their plans without an instrument to extract reliable or historical data. They rely on "in-house developments" that are usually Excel spreadsheets with a basic database, or they struggle with SAP PM, which often serves as a major roadblock in industries like defence.
Pinboard planning leaves gaps
The standard approach is pen and paper. Maintenance plans created in Excel are printed out and hung on a pinboard in the workshop. Tasks are ticked off to show they were "done", but the documentation lacks detail.
Because there is no record of what was actually renewed, what was found during the check, or what was left incomplete, these slips of paper disappear or land in a folder where they are never reviewed. Very few people ever go back to leaf through those folders to obtain information.
Losing your "knowledge carriers"
This setup forces a dangerous reliance on "knowledge carriers". Departments depend on experienced employees who have looked after a system for 10 years. That person knows exactly what to do, but the knowledge is stored only in their head. If that employee is ill, on holiday, or absent, the knowledge is inaccessible.
When these people eventually leave or retire, that experience goes with them. This causes the department's quality to sag and stay there for years until a new level of experience is rebuilt from scratch.
The biggest mistake companies make is believing the current situation is sufficient because "it has always worked like this", and it’s this belief that stops change.
Acknowledging "garbage in, garbage out"
Success requires acknowledging the hard reality of input/output: the "garbage in, garbage out" principle. Any system is a tool for your employees, and its value depends entirely on the diligence of the data they enter.
If the documentation doesn't change, the results will remain exactly as they are now, and this requires a cultural shift.
Communication lags create a 15-minute gap
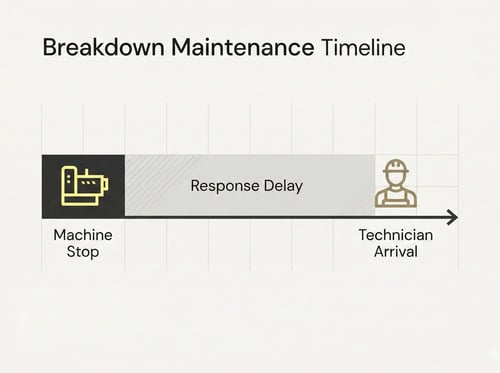
When a system stands still, the breakdown of the process happens in a predictable chain. The machine operator or production employee realises the stop and informs the production manager or shift supervisor first.
Analysis takes longer than you think
Because a technician is rarely on site the moment it happens, this report travels to the technical department, usually by telephone. By the time a technician is called, reaches the site, and begins to analyse the situation, at least 15 minutes of downtime has already been generated.
In an emergency, this analysis phase often stretches to 30 minutes or longer. The team has to determine if the problem is electrical or mechanical, which spare parts are required, and how many people are needed to carry out the work. In parallel, technical leadership must consult with production to manage the flow.
They discuss whether to brake or divert the material flow and how to minimise losses through manual handling while the repair is underway.
Documentation is non-existent during these phases. Steps are initiated and repairs are made, but nothing is recorded or traceable. This lack of data makes the event impossible to evaluate in retrospect.
This blindness extends to the warehouse. Spare parts like bearings or belts are booked out, but often without recording which system they were used for or which specific job they supported.
In the heat of the moment, documenting these details interests no one as long as production restarts.
How the backlog becomes invisible
This environment creates an invisible backlog of maintenance. Under production pressure, it's common for 20 to 30 maintenance tasks to be skipped because the priority is to "keep running".
Without a system, there is no way to know exactly how many tasks have been missed until a major failure occurs. This forces the company to rely entirely on their knowledge carriers, which turns problematic if they are absent or have quit.
Buyers often hesitate to fix this because they fear they must enter "5,000 data points" before seeing value. The reality of the current process, however, is that the lack of even basic data entry creates a cycle of constant coordination chaos.
Paying the price for the "buffer" illusion
Most production companies operate under the "buffer" illusion. They believe they can absorb a 30-minute malfunction due to various factors in their production design. But realistically, standstills start at 30 minutes and often drag upward to 1.5 hours. These events are annoying and expensive, particularly as the problem moves further along the production process.
A failure in the early stages has a lower impact, but the closer the product gets to completion, the higher the cost of every minute lost.
In this reactive state, the "quick fix" eventually fails. You reach a point where you have no choice but to take extensive repair and maintenance measures that can take hours. This leads to the "last groove" strategy, where the system is run down to its limit to exhaust production output without any effort to extend its life.
This stands in direct contrast to an asset care strategy, where service life is stretched to ensure long-term cost-efficiency and avoid early reinvestment in new systems.
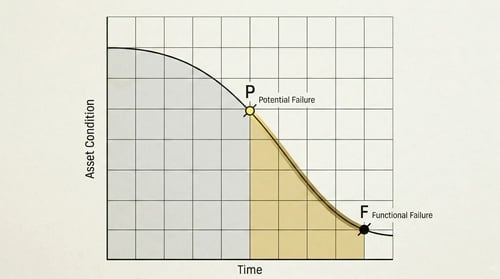
Counting the financial and moral toll
The costs of these are both financial and moral. Playing firefighter every day wears out the team. A high stress level and constant reactive work create a bad atmosphere, which leads to poor quality work and increases the degree of wear on the systems, promoting even more standstills and failures.
It’s a self-reinforcing negative feedback loop.
Small stops accumulate to 1.5 hours
Plant managers and managing directors frequently underestimate this, viewing maintenance as the "last link in the chain". Their goal remains "preventing the worst" rather than optimising the plant. But even small malfunctions, like the 5 or 10-minute stops that occur every day, accumulate.
If no one tracks them, the company loses 1.5 hours of production by the end of the day. Without a way to track these patterns, that time is lost forever.
Building a data-driven foundation
The transition to proactive maintenance begins with a solid data basis. The CMMS forms the basis of this transition, making smooth documentation possible and allowing for decisions based on real figures.
This system needs a certain amount of time to establish itself, as the data must be created first before it can serve as a foundation for future choices.
Pinpoint malfunctions using OEE
OEE plays a significant role in identifying technical malfunctions and problems more precisely. Because the system provides access to the PLC, it transmits specific fault messages that serve as an evaluation and analysis tool during standstills.
Instead of seeing a general error, the technical department gets a precise indication of a specific sensor, assembly, or technical component. This offers an additional depth that enables the team to identify problems faster.
Forecast future needs with Manufacturing Intelligence
Maintmaster Manufacturing Intelligence (MI) supports continuous improvement. It evaluates existing data to make forecasts and define measures for the future. This allows a company to extract the last few per cent of efficiency and quality from a system that is already performing at a high level.

IoT sensors monitor inaccessible parts
For built-in or covered system components that are production-relevant but inaccessible, like fast-running conveyor belts or dangerous sawing processes, IoT vibration sensors make a difference. These sensors provide reliable data on the condition of the system from the outside.
The system effectively communicates with the maintenance technician, providing the information needed to decide whether a repair window is necessary or if the process can continue smoothly. AI recognises when different employees describe the same problem, even if they use different wording or languages, and provides solution tips.

Throughout this process, the "garbage in, garbage out" principle remains the standard. The software is a tool for the employees to use, and its value is tied directly to their diligence in entering quality data. This practice gets a whole lot easier in Maintmaster with pre-populated, required, and templated fields.
From reactive chaos to proactive control
The first change in a maturing maintenance department is a sharpened view of time management. Customers begin to evaluate their maintenance cost ratio and track the shift from reactive to preventive hours. Technicians use the system to prove their productivity, including documenting when they spend 3 hours a day on non-maintenance activities. This documentation makes the actual workload traceable and provides the data needed to justify shifts in staffing.
This traceability makes it easier to see the future. The technical department uses collected experience and reliable data to look ahead and avoid malfunctions before they happen. The debate over whether a CMMS is necessary usually settles itself after the first 50 to 100 jobs are reported back. At that point, the conversation shifts from "why do we need this?" to "what else can we integrate?".
Saving time on spare parts
A concrete example of this maturity is the spare part win. The system automatically adds booked-out articles to the bill of materials (BOM) for a specific system. When a standstill arises, a technician sees the required article immediately in the system. They can send 1 person to the warehouse for the part while others handle the removal of the broken component. This functionality saves significant time during the critical moments of a standstill.
Looking back to reconstruct history
Furthermore, the system allows for the reconstruction of history. A team can look back 2 months at a specific malfunction or maintenance task to see what was found and whether the follow-up orders were actually remedied. This level of data access removes the stress of the unknown.
Once the firefighting is under control, the team realises the shift in their working climate, and there is no desire to return to the previous state of constant pressure.
Breaking the "toolbox trap" mindset
Reactive maintenance creates a specific type of pressure. It’s like having a huge toolbox, but the moment you need to use it, you're missing exactly the right tool. No matter how well-trained or prepared a technician is, a reactive environment removes the possibility of preparation. This forces the team into a camp defined by stress, pressure, and a constant compulsion to act.
There is a tendency to rely on the statement, "We have always done it like this so far and it has always worked". This mindset inhibits the department's ability to take the next step.
It ignores the reality that malfunctions are part of everyday life in a production plant. They are expected. But these malfunctions accumulate. Without tracking, a company ignores the fact that 5 or 10-minute stops can result in losing 1.5 hours of production by the end of the day.
Moving toward manufacturing excellence
As your company matures with a CMMS, focus shifts. Planned activities appearing in the system as work orders are viewed differently. Instead of seeing a task as "just a job" to be finished, the team recognises the value of a single preventive task in helping the plant produce more efficiently and successfully.
The long-term value of the system lies in the traceability of data. Being able to reconstruct a malfunction or the outcome of a maintenance task months later provides a reason for why things happen.
Even if a standstill occurs, which will happen regardless of the system, the technician can refer to the job history to see when work was done, what was found, and whether it was remedied or reworked.
Stretch service life with asset care
Correctly solving the problem of reactive maintenance stops the "last groove" strategy of running machines into the ground. It allows for an asset care strategy that stretches service life and ensures cost-efficiency.
Ultimately, the technical department moves from damage limitation to a structured way of working. This transition removes the moral wear on the team and ensures that the technical department is no longer just "getting the cow off the ice", but actively driving the success of the production process.


